El mejor procesador de esta segunda generación del 3D V-caché ha llegado, el nuevo Ryzen 9 9950X3D de AMD lo cual es considerado el mejor procesador para gaming y creación de contenido. Mayor rendimiento y un excelente manejo de temperatura es lo que puedo decir de entrada pero antes de llegar a los resultados exploremos un poco sobre esta nueva tecnología.


Desde su introducción, la tecnología 3D V-Cache surgió como un experimento con la ambición de mejorar el rendimiento en juegos sin comprometer la eficiencia térmica del procesador. El Ryzen 7 9800X3D se convirtió en el favorito de muchos jugadores, consolidándose como una opción legendaria dentro de la comunidad. Sin embargo, la llegada de una nueva generación plantea lo que ya hemos visto en el anterior X3D.
Después de semanas de pruebas me ha dejado claro que es la evolución que necesitábamos en el momento perfecto. Desde mi experiencia con el Ryzen 9 9950X3D, pude darme cuenta que este maneja muy bien el rendimiento en cuanto a su hermano menor pero sobre todo manteniendo unas temperaturas que dan mucha envidia. En la siguiente imagen veremos una especie de diagrama que confirma más o menos como este caché está distribuido y como ayuda bastante al rendimiento.

En esta segunda generación, el 3D V-Cache ahora está ubicado debajo del chip, en lugar de encima, lo que reduce su dependencia del rendimiento en función de las altas temperaturas. Esto permite mantener un mayor pico de rendimiento sin comprometer la estabilidad térmica.

Si bien en la generación anterior esto no era un problema crítico, el hecho de que el rendimiento estuviera tan ligado a la temperatura hacía que jugar con los límites térmicos fuera un riesgo (literalmente). Con este nuevo diseño, se obtiene un mejor equilibrio entre potencia y eficiencia, asegurando un desempeño más estable y consistente.
Lo más destacable, y explicado en términos simples, es que esta tecnología reduce la latencia, lo que se traduce en más FPS y una experiencia de juego más fluida. Es fundamental recordar que, al armar una PC, el procesador debe ser la pieza más potente y optimizada, ya que las tarjetas gráficas cambian constantemente con nuevas versiones y modelos.

Lo real aquí es que el nuevo procesador pretende sacar al máximo el rendimiento de todo el equipo sin siquiera llegar al 100% de todo su esfuerzo. Debo mencionar que este procesador se encuentra por encima de la media que un gamer pudiera necesitar y no necesariamente utilizaremos toda esta potencia a menos un creador de contenido le de un uso mucho mayor. Las pruebas que realizaremos estarán enfocadas únicamente en el tema gaming agregando ciertos benchmarks de los más conocidos.
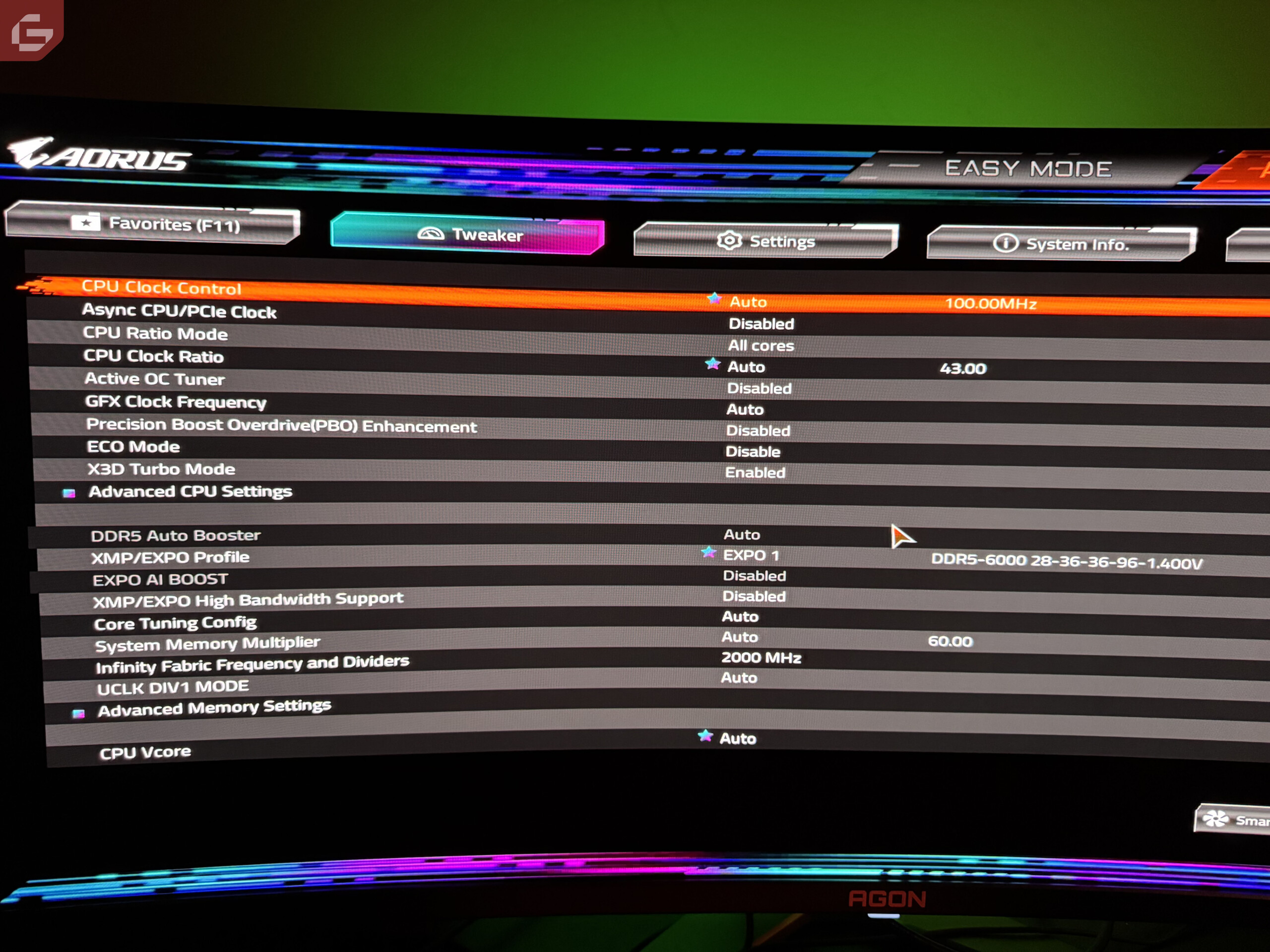
Todas las pruebas fueron realizadas de manera estándar, el modo Auto OC de el AMD Ryzen Master estuvo activado todo el tiempo. Ninguna mejora de escalado (FSR) estuvo activada, el balance de energía de la PC estuvo siempre en balanceado. La PC utilizada para las pruebas es la siguiente:

- Motherboard: Gigabyte X870E AORUS MASTER
- RAM: GSkill Trident Z5 RGB 2x16GB DDR5-6000 con AMD Expo
- Cooler: AIO be quiet! Light Loop 360mm
- Case: be quiet! Light Base 600 LX
- GPU: ASUS TUF Radeon RX 7700 XT OC Edition
- Monitor: AOC AGON PRO QD-OLED AG346UCD
- SSD: Samsung 990 PRO 1TB
- SSD 2: FireCuda 540 PCIe Gen5 NVMe 2TB
- PSU: Be Quiet! Pure Power 12 M Fully-modular
- Sistema Operativo: Windows 11 (Ultima versión)
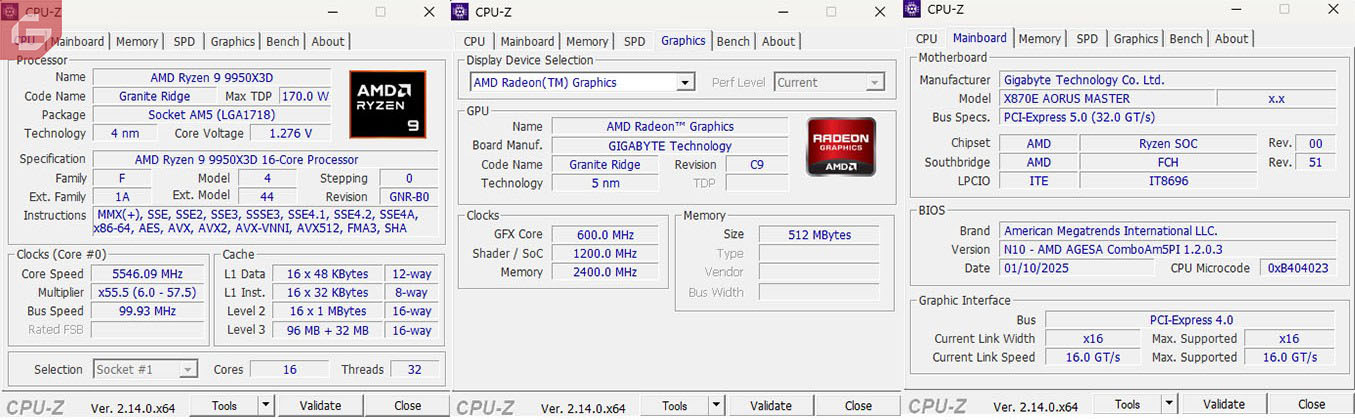
En cuanto a la memoria RAM, estas cuentan con una latencia CL28 y están diseñadas específicamente para trabajar con AMD Expo. Se utilizó la configuración AMD Expo 1, que ofrece el máximo rendimiento posible, y todos los ajustes fueron realizados directamente desde el BIOS.
Respecto a la GPU, aunque se trata de la versión OC de Asus, no se aplicó ningún overclock adicional. Para la refrigeración, se utilizó el nuevo Light Loop de be quiet! en su versión de 360mm, asegurando así un rendimiento térmico óptimo y manteniendo temperaturas bajo control incluso en cargas exigentes.
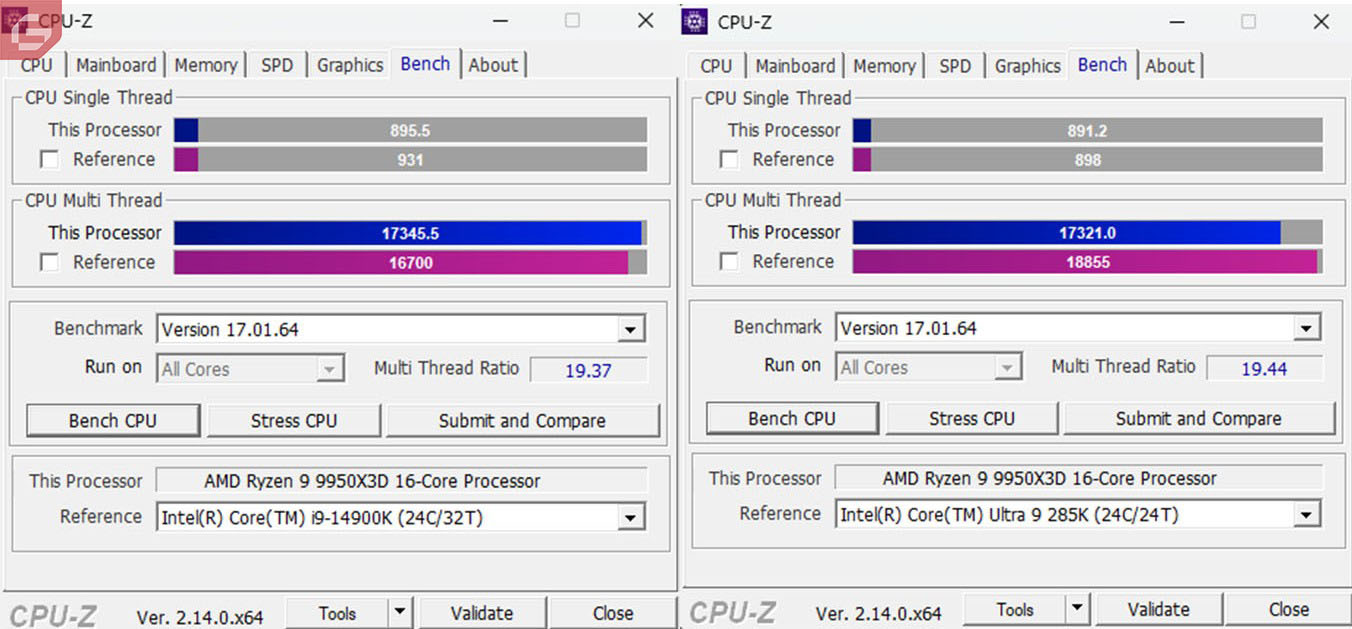
Las primeras pruebas que tenemos son los benchmarks tradicionales. Dentro de ellos tenemos CPUz y este compara los dos últimos procesadores de mayor gama de Intel. AMD en este caso supera bastante al i9-14900 K por una diferencia notable mientras que el Core Ultra 9 si supera al Ryzen 9 9950x3D pero por muy poco.
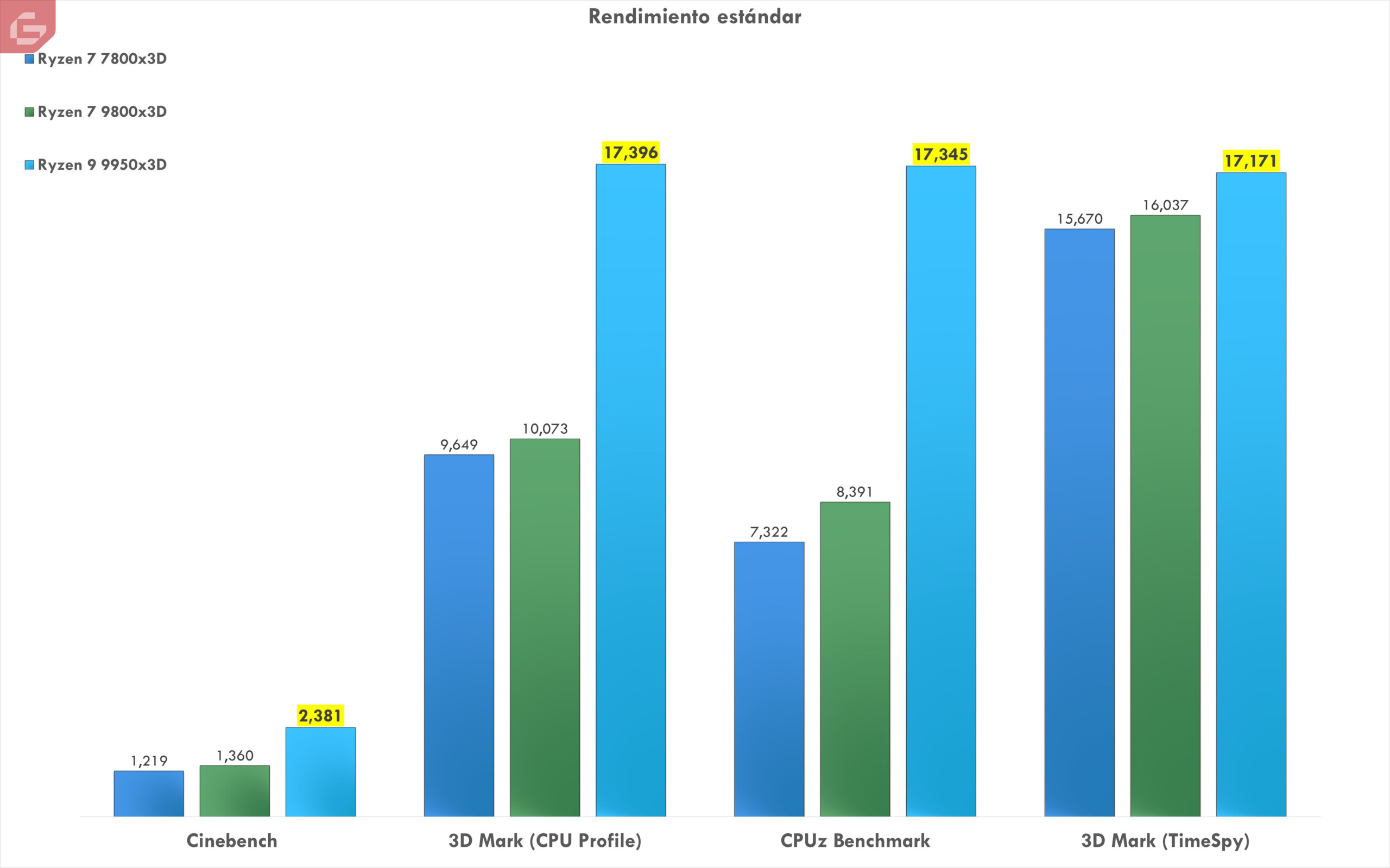
Dentro de toda la combinación adicional, tenemos el mismo Cinebench y 3D Mark (TimeSpy y CPU Profile). Estos básicamente prueban dos versiones del procesador. Su manejo por core individual y todos juntos. La puntuación (colocando solo los x3D que hemos probado) se puede ver como el mismo supera bastante a sus antecesores y muestra una buena soberanía entre ellos.
Las pruebas de rendimiento en videojuegos han representado un verdadero desafío. Se realizaron mediciones en 1080p y 1440p, abordando tanto el desempeño competitivo como una experiencia más enfocada en la calidad visual. FSR no fue activado, permitiendo observar el rendimiento nativo del hardware en distintos juegos y motores gráficos.
Entre los títulos seleccionados se incluyen Fortnite, Microsoft Flight Simulator, Starfield y Space Marine 2, este último con una alta demanda de hardware. Para complementar los resultados, se presentan capturas de pantalla de cada juego, seguidas de un desglose comparativo con otros procesadores de AMD, destacando las mejoras en rendimiento generacional.


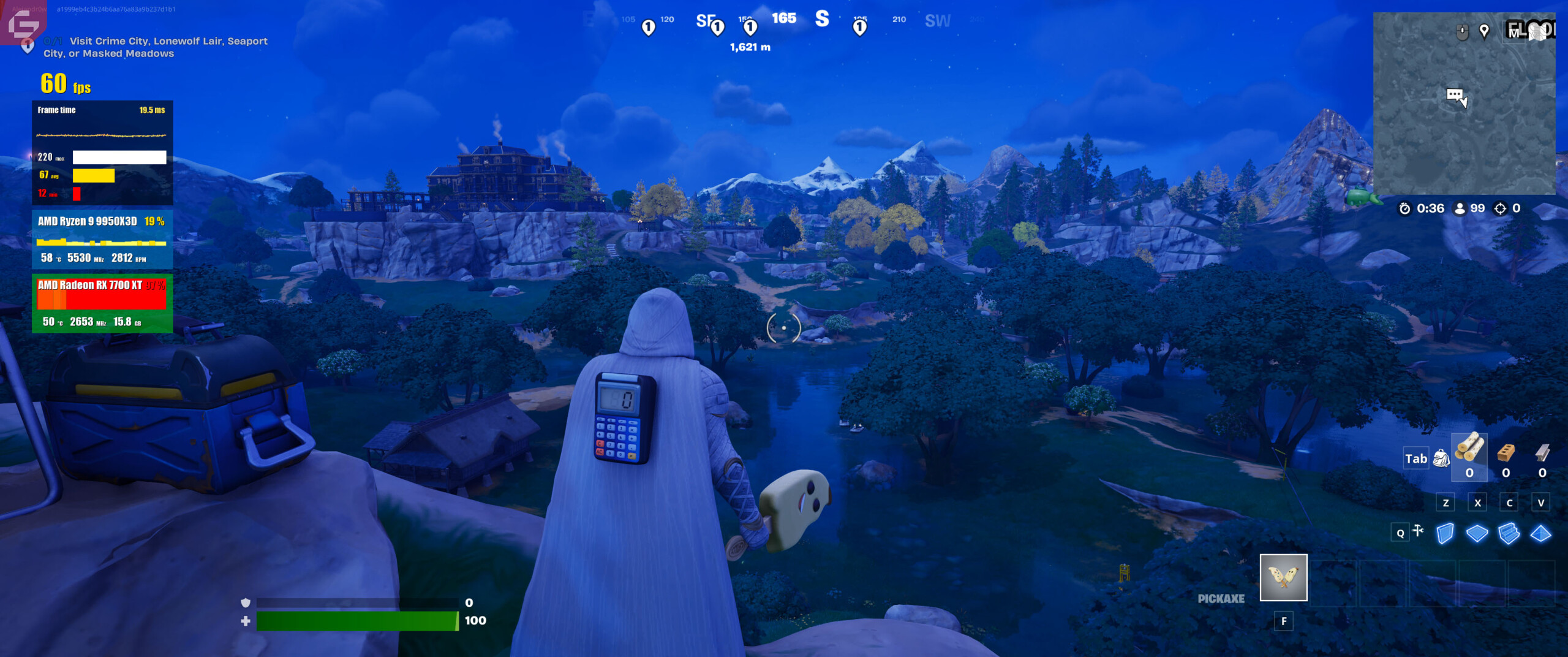
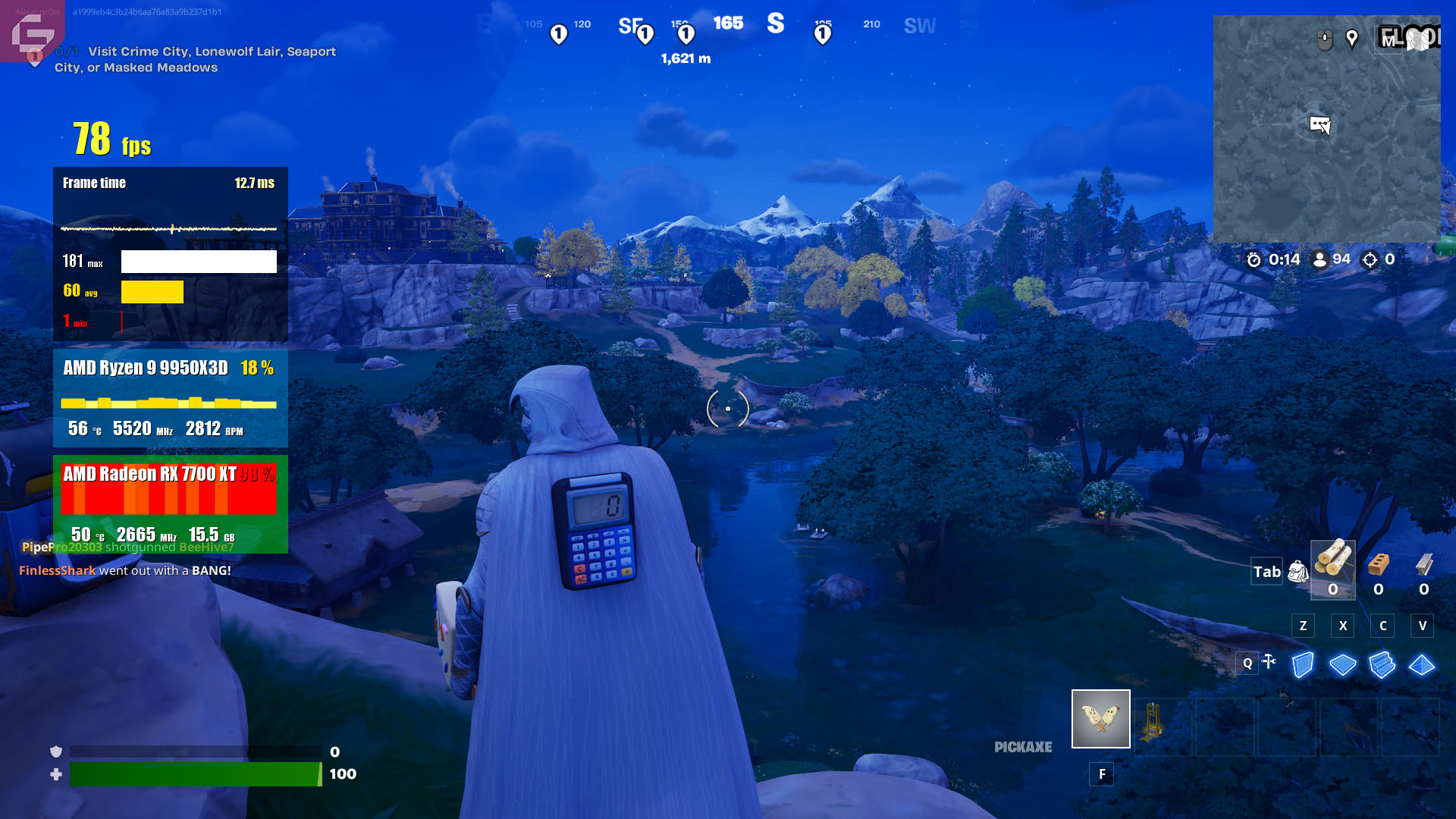




Ahora tenemos una cantidad de juegos por desglosar. Aquí están agrupados los procesadores x3D recientes y la intención es ver realmente la mejora de uno con otro. Las resoluciones 1080p y 1440p estarán separadas en cada uno. Básicamente entre un 9% y un 11% de mejora en los FPS en comparación al 9800x3D lo cual para mi es bastante razonable viniendo de que son tecnologías nuevas y aunque la diferencia no es mucha, coloca a este Ryzen 9 como el mejor de todos hasta el momento.
Las mejoras son notorias y probablemente con una tarjeta de video la diferencia fuese mucho mejor. El que más mejoró de todos son juegos como Forza Horizon 5 y el mismo Horizon Zero Dawn. Básicamente todos los juegos mejoraron bastante en comparación al Ryzen 7 9800x3D pero ya la generación anterior de procesadores x3D acaba de quedarse un poco atrás.
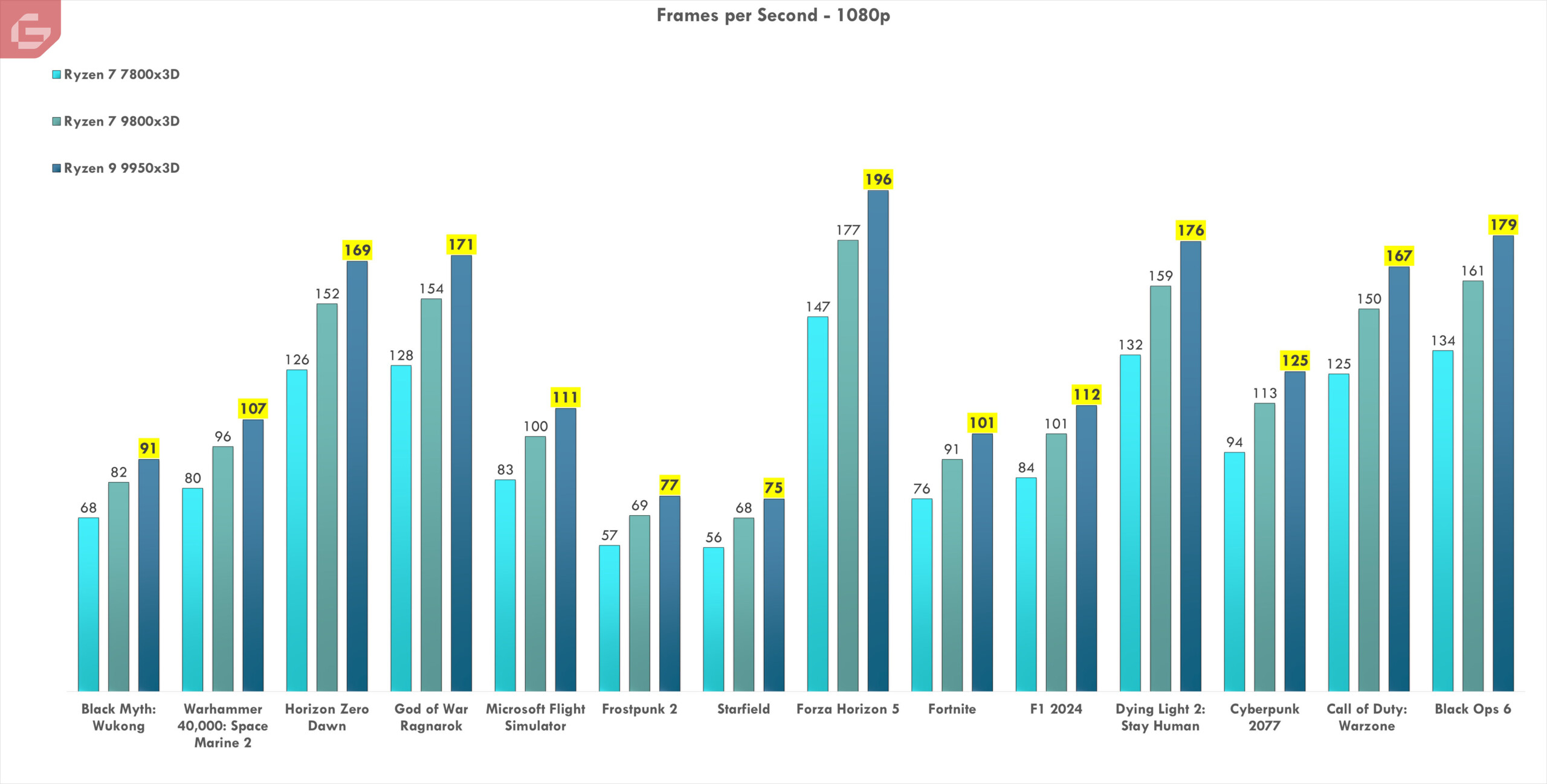
Pudiéramos decir que la relación precio de este procesador con su versión más joven (Ryzen 7 9800x3D) es bastante distinta. Para mi este es un poco más enfocado al gaming en general mientras que este Ryzen 9 9950x3D es una mezcla entre gaming en su máxima expresión con el control de los multiprocesos o incluso para creadores de contenido.
En conclusion
El nuevo Ryzen 9 9950x3D de AMD es hasta ahora el procesador más potente para gaming y la creación de contenido. La diferencia entre el Ryzen 7 9800x3D no es tan notoria y con un precio tan superior deja claro que este CPU es un poco más exotico. El rendimiento es real dejando atrás incluso a los mejores procesadores Intel, el manejo de la temperatura es bastante aceptable incluso bajo pruebas intensas por varios minutos. Esta segunda generación del 3D V-Cache nos ha dejado claro que se puede alcanzar un buen rendimiento sin sacrificar tanto, poniendo al fabricante como el líder en procesadores hasta el momento. Este review fue realizado con el hardware suministrado por AMD.