Los modelos de lenguaje han avanzado mucho desde GPT-2 y ahora los usuarios pueden implementar de forma rápida y sencilla modelos de lenguaje altamente sofisticados con aplicaciones fáciles de usar como LM Studio. Junto con AMD, herramientas como estas hacen que la IA sea accesible para todos sin necesidad de conocimientos técnicos o de codificación.
LM Studio se basa en el proyecto llama.cpp, que es un marco muy popular para implementar modelos de lenguaje de forma rápida y sencilla. No tiene dependencias y se puede acelerar utilizando solo la CPU, aunque tiene disponible la aceleración de GPU. LM Studio utiliza instrucciones AVX2 para acelerar modelos de lenguaje modernos para CPU basadas en x86.
¿Qué son los modelos de lenguaje de gran tamaño? Los modelos de lenguaje de gran tamaño, también conocidos como LLM, son modelos de aprendizaje profundo de gran tamaño que se entrenan previamente con grandes cantidades de datos. El transformador subyacente es un conjunto de redes neuronales que constan de un codificador y un decodificador con capacidades de autoatención.
AMD Ryzen™ AI acelera estas cargas de trabajo de última generación y ofrece un rendimiento líder en aplicaciones basadas en llama.cpp como LM Studio para portátiles x861. Vale la pena señalar que los LLM en general son muy sensibles a las velocidades de la memoria. En nuestra comparación, el portátil Intel en realidad tenía una RAM más rápida a 8533 MT/s, mientras que el portátil AMD tiene una RAM de 7500 MT/s.
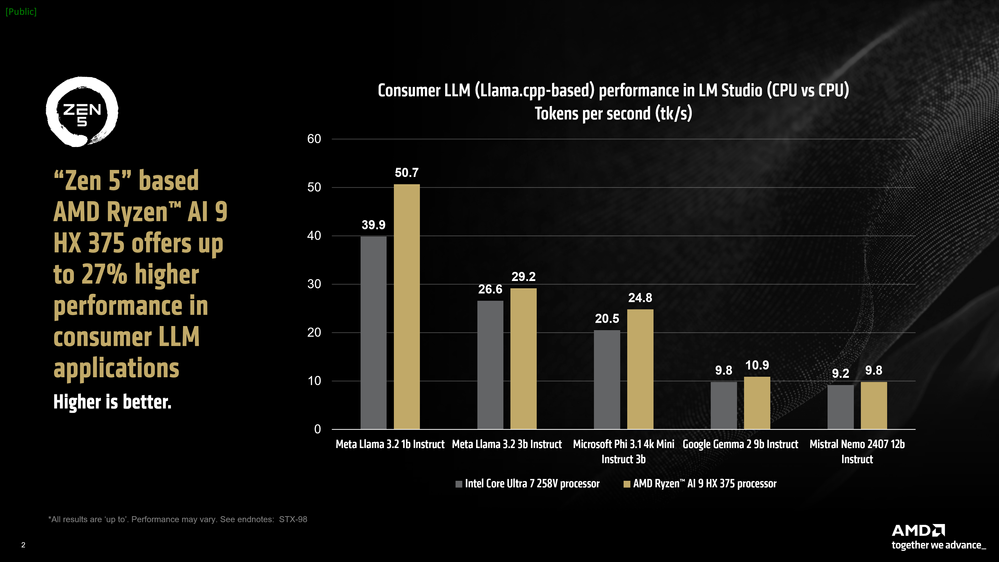
Gráfico de barras que compara el rendimiento de varios procesadores en aplicaciones LLM para consumidores, destacando el rendimiento superior del AMD Ryzen AI 9 HX 375.
A pesar de esto, el procesador AMD Ryzen™ AI 9 HX 375 logra un rendimiento hasta un 27 % más rápido que su competencia cuando se analizan los tokens por segundo. Como referencia, los tokens por segundo o tk/s es la métrica que denota la rapidez con la que un LLM puede generar tokens (que corresponde aproximadamente a la cantidad de palabras impresas en la pantalla por segundo).
El procesador AMD Ryzen™ AI 9 HX 375 puede alcanzar hasta 50,7 tokens por segundo en Meta Llama 3.2 1b Instruct (cuantificación de 4 bits).
Otra métrica para evaluar modelos de lenguaje grandes es el «tiempo hasta el primer token», que mide la latencia entre el momento en que envías un mensaje y el tiempo que tarda el modelo en comenzar a generar tokens. Aquí vemos que en modelos más grandes, el procesador Ryzen™ AI HX 375 basado en AMD «Zen 5» es hasta 3,5 veces más rápido que un procesador comparable de la competencia1.
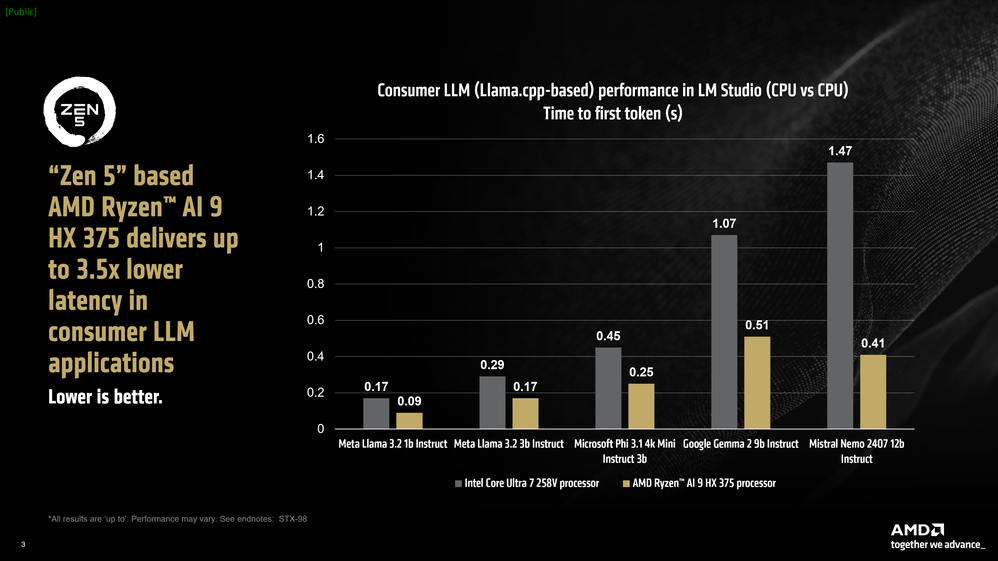
Gráfico que compara la latencia en aplicaciones LLM para consumidores para varios procesadores, destacando el rendimiento de AMD Ryzen AI 9 HX 375.
Uso de memoria gráfica variable (VGM) para acelerar el rendimiento del modelo en Windows
Cada uno de los tres aceleradores presentes en una CPU AMD Ryzen™ AI tiene su propia especialización de carga de trabajo y escenarios en los que se destacan. Las NPU basadas en la arquitectura AMD XDNA™ 2 brindan una increíble eficiencia energética para la IA persistente mientras se ejecutan cargas de trabajo Copilot+, y las CPU brindan una amplia cobertura y compatibilidad para herramientas y marcos: es la iGPU la que a menudo maneja las tareas de IA a pedido.
LM Studio presenta un puerto de llama.cpp que puede acelerar el marco utilizando la API Vulkan independiente del proveedor. La aceleración aquí generalmente depende de una combinación de capacidades de hardware y optimizaciones de controladores para la API Vulkan. Activar la descarga de GPU en LM Studio resultó en un aumento de rendimiento promedio del 31 % en el rendimiento de Meta Llama 3.2 1b Instruct en comparación con el modo solo CPU. Los modelos más grandes como Mistral Nemo 2407 12b Instruct, que están limitados por el ancho de banda en la fase de generación de tokens, experimentaron un aumento del 5,1 % en promedio.
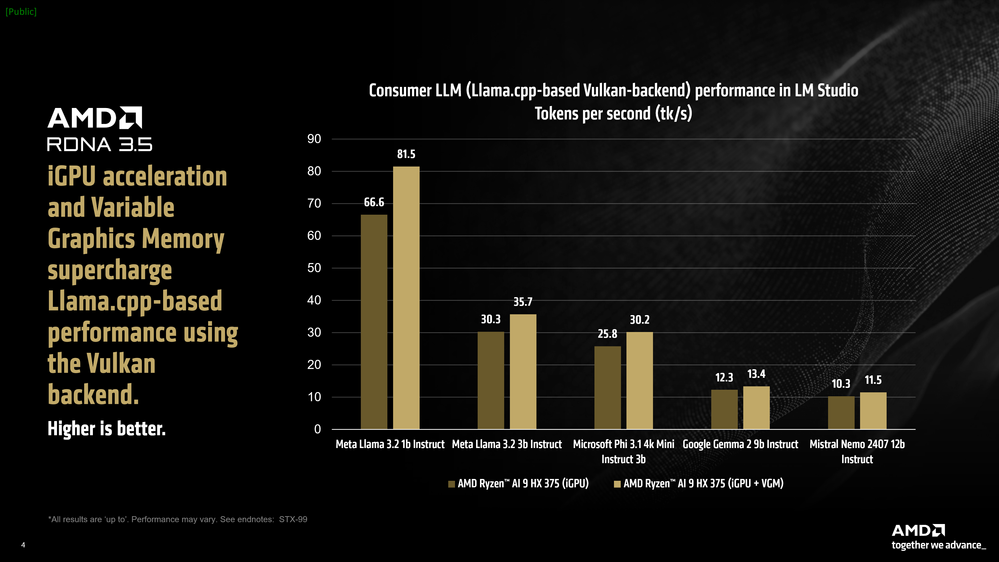
Gráfico de barras que compara el rendimiento basado en Llama.cpp en LM Studio utilizando el backend Vulkan, que muestra tokens por segundo para varios modelos.
Observamos que al usar la versión de llama.cpp basada en Vulkan en LM Studio y activar la descarga de GPU, el procesador de la competencia tuvo un rendimiento promedio significativamente menor en todos los modelos probados, excepto uno, en comparación con el modo solo CPU. Por este motivo y en un esfuerzo por mantener la comparación justa, no hemos incluido el rendimiento de descarga de GPU del Intel Core Ultra 7 258v en el back-end Vulkan basado en Llama.cpp de LM Studio.
Los procesadores AMD Ryzen™ AI Serie 300 también incluyen una función llamada Memoria gráfica variable (VGM). Por lo general, los programas utilizarán el bloque de 512 MB de asignación dedicada para una iGPU más el segundo bloque de memoria que se encuentra en la parte «compartida» de la RAM del sistema. VGM permite al usuario extender la asignación «dedicada» de 512 hasta el 75 % de la RAM del sistema disponible. La presencia de esta memoria contigua aumenta significativamente el rendimiento en aplicaciones sensibles a la memoria.
Después de activar VGM (16 GB), notamos un aumento promedio adicional del 22 % en el rendimiento en Meta Llama 3.2 1b Instruct para un total neto de velocidades promedio un 60 % más rápidas, en comparación con la CPU, utilizando la aceleración de iGPU cuando se combina con VGM. Incluso los modelos más grandes como Mistral Nemo 2407 12b Instruct experimentaron un aumento del rendimiento de hasta el 17 % en comparación con el modo solo CPU.
Comparación lado a lado: Mistral 7b Instruct 0.3
Si bien la computadora portátil de la competencia no ofreció una aceleración utilizando la versión basada en Vulkan de Llama.cpp en LM Studio, comparamos el rendimiento de iGPU utilizando la aplicación propia Intel AI Playground (que se basa en IPEX-LLM y LangChain), con el objetivo de hacer una comparación justa entre la mejor experiencia LLM disponible para el consumidor.
https://youtu.be/1v7_cDKyk74
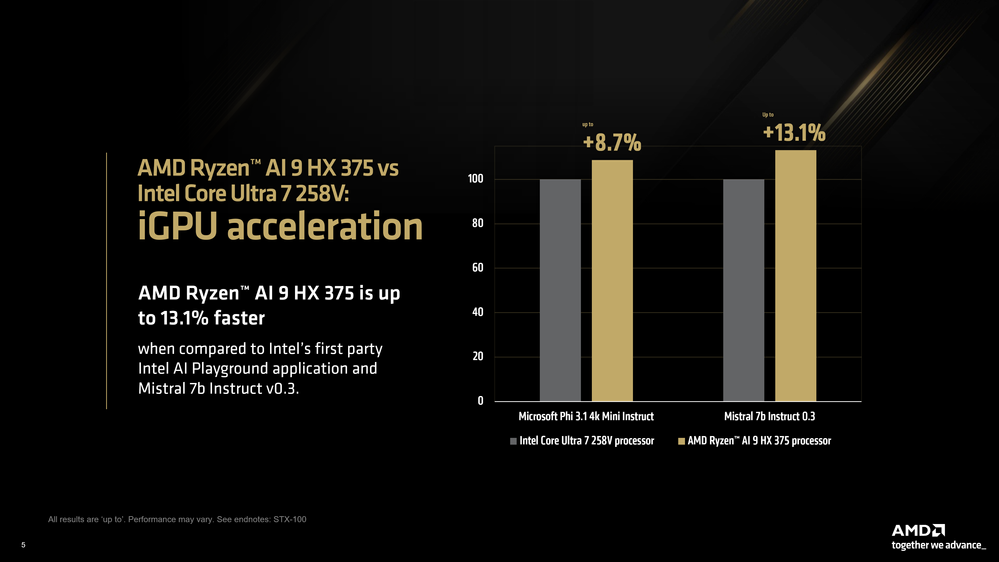
Usamos los modelos provistos con Intel AI Playground, que son Mistral 7b Instruct v0.3 y Microsoft Phi 3.1 Mini Instruct. Usando una cuantificación comparable en LM Studio, vimos que el AMD Ryzen™ AI 9 HX 375 es 8.7% más rápido en Phi 3.1 y 13% más rápido en Mistral 7b Instruct 0.3.
Comparación de AMD Ryzen AI 9 HX 375 e Intel Core Ultra 7 258V que muestra el rendimiento de aceleración de iGPU, destacando las ventajas de velocidad.
AMD cree en avanzar la frontera de la IA y hacer que la IA sea accesible para todos. Esto no puede suceder si los últimos avances de IA están detrás de una barrera muy alta de habilidad técnica o de codificación, que es por eso que las aplicaciones como LM Studio son tan importantes. Además de ser una herramienta rápida.
Estas aplicaciones, que son una forma sencilla y sin complicaciones de implementar LLM de forma local, permiten a los usuarios experimentar modelos de última generación prácticamente desde el momento en que se lanzan (suponiendo que el proyecto llama.cpp admita la arquitectura).
Los aceleradores de IA AMD Ryzen™ ofrecen un rendimiento increíble y la activación de funciones como la memoria gráfica variable puede ofrecer un rendimiento aún mejor para los casos de uso de IA. Todo esto se combina para ofrecer una experiencia de usuario increíble para los modelos de lenguaje en una computadora portátil x86.